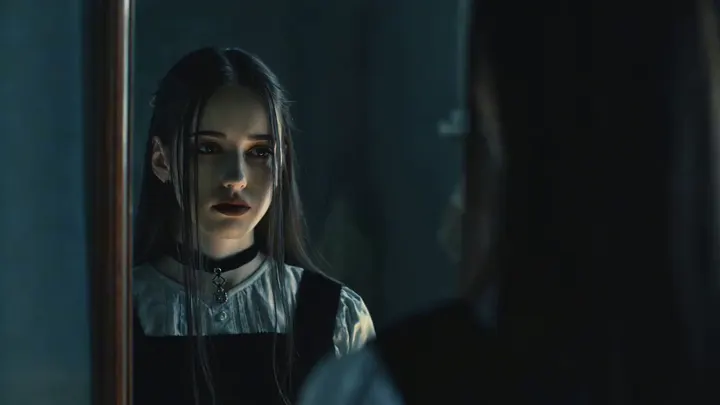Better emotional performance and expression.
AI characters often look flat or fake—emotion doesn’t land. Seedance 2.0 improves micro-expressions and body language so characters can show joy, sadness, surprise, or anger in a more natural way; eyes, mouth, and gesture all read better. If you want AI characters with real “acting,” 2.0 gets you there.
Emotional performance is improved for more expressive and nuanced character delivery.
How it works: the model generates characters whose facial micro-expressions (eye movement, mouth shape, brow position) and body language (gesture, posture, movement intensity) respond to the emotional context described in your prompt. Instead of flat, neutral faces, characters can express joy, sadness, surprise, anger, or subtler states like hesitation or curiosity.
When to use this: virtual-human and VTuber content where emotional connection drives audience engagement; brand storytelling where character emotion carries the narrative; educational content where an instructor character needs to appear warm and approachable; social-media shorts where expressive characters boost watch-time and shares.
Tips and practical notes: be specific about the emotion and its intensity in your prompt — 'gentle smile with a slight head tilt' produces more nuanced results than just 'happy.' For dialogue scenes, pair emotion expression with native audio to get synchronized vocal tone and facial expression. The model handles transitions between emotions within a single shot (e.g., 'starts surprised then breaks into laughter'), which is useful for short narrative content. Combine with character consistency to ensure the same character maintains its identity while expressing different emotions across shots.
Reference Example
Virtual Idol AgencyVirtual Human/VTuber
AI Virtual Human Emotional Live Streaming
Reported context
Traditional virtual avatars have rigid expressions and monotonous emotions, making it difficult to establish emotional connections with viewers; interaction retention rate is low
Reported use
Used emotion expression controls so AI virtual humans could show richer expressions and body language during live content.
Cited / reported data
Public case recaps cite livestream interaction rising 180%, average viewing time tripling, follower count exceeding 1 million, and endorsement revenue growing 5x.
✦Reading note:Micro-expression and body-language controls made the performances easier to read.
Source basis
Illustrative cases on this site are compiled from public campaign recaps and secondary reporting available at the time of writing.
Time context
Metrics reflect the reported campaign period and should not be treated as current performance benchmarks.
Data note
Brand names and figures are cited for explanatory use only, not as endorsements, guarantees, or independently audited results.