Squadra tattica spagnola
Voce e suono accurati
Ripresa fissa. Capitano in spagnolo: Raid tra tre minuti! Biondo controlla le armi, capelli verdi tiene la torcia tattica. Compagno nero: Flanking? Capitano: Come sempre, tieni uno per interrogatorio.
Dati di riferimento
Genera voce, ambiente sonoro e musica insieme all'output video. Come funziona: anziché generare video muto e aggiungere l'audio in post-produzione, il modello produce immagine e suono nello stesso passaggio. Legge il contesto visivo — movimenti labiali dei personaggi, tipo di ambiente, intensità dell'azione — e genera voce, ambiente, effetti sonori o musica di sottofondo corrispondenti. I prompt testuali possono guidare lo stile audio ('BGM elettronico ritmato', 'suoni ambientali morbidi di foresta', 'voiceover femminile in inglese'). Quando usarlo: produzione pubblicitaria dove ogni variante necessita di voiceover localizzato; shorts per social media dove BGM e timing contano ma la sincronizzazione manuale è troppo lenta; prototipazione di scene dove vuoi valutare immagine e suono insieme prima di investire in audio professionale; contenuti multilingue dove lo stesso video necessita di voiceover in lingue diverse. Suggerimenti pratici: per i migliori risultati di lip-sync, mantieni i volti dei personaggi chiaramente visibili e non ostruiti. Specifica la lingua e il tono della voce nel tuo prompt — 'narratore maschile calmo in giapponese' dà risultati migliori di un semplice 'aggiungi voce'. Quando combini l'audio nativo con la sincronizzazione musicale, il modello può gestire contemporaneamente l'allineamento al beat della BGM e il dialogo. Controlla l'audio al primo passaggio per individuare problemi di timing prima di generare molte varianti.
Se un video necessita ancora di musica di sottofondo, atmosfera o dialoghi con sincronizzazione labiale, il modello può generare immagini e audio insieme in modo che le scelte audio possano essere riviste nello stesso passaggio.
Voce e suono accurati
Squadra tattica spagnola
Seedance 2.0 genera voce, effetti sonori e musica insieme al video in un unico passaggio — con lip-sync, supporto multilingue e un caso studio Unilever di produzione di massa.
CapacitàTutti gli esempi
- Musica di sottofondo per cavallo fish-eye (multi-video)
- Documentario sull'edificio per uffici VO
- Talk show su cani e gatti
- Yu opera Caso Chen Shimei
- Banda MV tramonto sulla scogliera
- Festa della famiglia latina
- Squadra tattica spagnola
- Riferimento vocale per la sveglia
- Tè delle bolle delle scimmie Sichuan
- Montagna della fiamma del Re Scimmia
Guide correlate
Guida
Che cos'è Seedance 2.0 di ByteDance? Sito ufficiale, data di rilascio e accesso
Panoramica attuale e pubblica di Seedance 2.0 di ByteDance: sito ufficiale, rilascio del 12 febbraio 2026, segnali di accesso tramite Dreamina, input multimodali, output 2K / 15 secondi e ciò che dipende ancora dalla superficie di accesso.
Guida apertaGuida
Seedance 2.0 Omni-Reference & Input Multimodale — Immagini, Video e Audio di riferimento spiegati
Seedance 2.0 ingresso multimodale: fino a 9 immagini, 3 video, 3 audio + testo. @ sistema tag per arbitrare le attività. Generazione audio-video nativo.
Guida apertaGuida
Seedance 2.0 Casi d'uso — Esempi reali per pubblicità, cinema, istruzione e altro
Seedance 2.0 casi di utilizzo: annunci di e-commerce, TVC, demo di prodotto, film previz, MV, istruzione, immobiliare, e breve narrazione. Basato su blog ufficiale e studi di casi di terze parti.
Guida apertaGuida
Promo videos stitched from multiple clips: workflow field notes
Honest workflow notes when a longer promo is built from several Seedance 2.0 generations: unified references, the per-clip duration cap, audio continuity, and dialogue pacing.
Guida apertaGuida
Seedance 2.0 Shot Design Workflow — Cinema-Grade Video Prompts
Master the 5-step shot design workflow for Seedance 2.0: from requirement analysis through visual diagnosis, six-element assembly, validation, to professional delivery. Includes 28+ director presets, three-layer lighting, and multi-segment storyboarding.
Guida apertaGuida
Short-Form Social Video with Seedance-Style Models — Reels, Shorts, TikTok-Class Pacing (2026)
Vertical aspect ratios, hook-first prompting, and audio loudness considerations for algorithmic feeds — third-party workflow notes.
Guida apertaCapacità correlate

Sincronizzazione musicale
Musica sincronizzata al ritmo e allineamento del ritmo.
Carica musica; i tagli video e il movimento si allineano al ritmo.
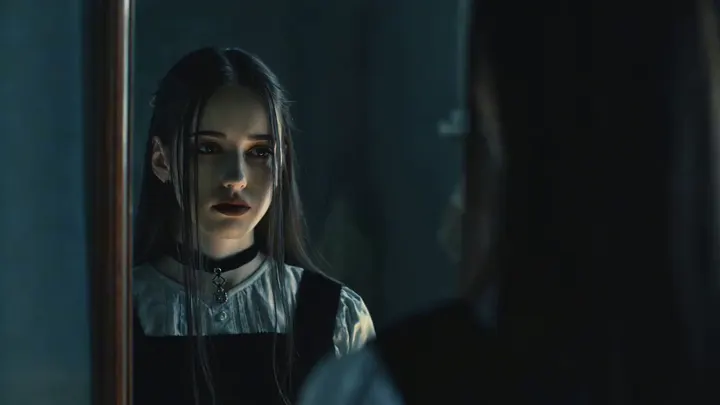
Espressione delle emozioni
Migliore prestazione ed espressione emotiva.
Il personaggio mostra gioia, tristezza, sorpresa; linguaggio naturale del viso e del corpo.

Montaggio video
Sostituzione, rifinitura e aggiunte di personaggi.
Integrazione, scambio di caratteri, estensione dello sfondo, aggiunta di elementi/remove; nessuna ripresa.