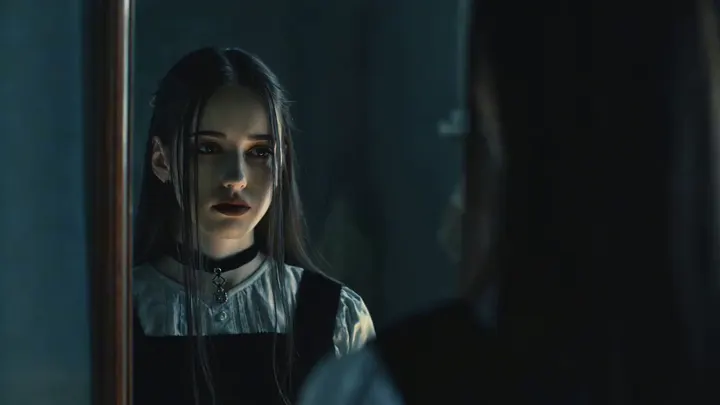Voce, effetti sonori, generazione musicale, riferimento vocale.
Musica di sottofondo per cavallo fish-eye (multi-video)
Breve videoAvanzatoRiferimento multi-video con generazione audio sincronizzata
Ripresa fissa, fish-eye centrale attraverso apertura circolare che guarda verso il basso, riferimento @video1 fish-eye, cavallo in @video2 guarda il fish-eye, riferimento @video1 movimento parlato, BGM riferimento @video3 audio.
Video di riferimento
1
Video di riferimento 1: Musica di sottofondo per cavallo fish-eye (multi-video)
2
Video di riferimento 2: Musica di sottofondo per cavallo fish-eye (multi-video)
3
Video di riferimento 3: Musica di sottofondo per cavallo fish-eye (multi-video)
Risultato generato
Risultato generato: Musica di sottofondo per cavallo fish-eye (multi-video) — Riferimento multi-video con generazione audio sincronizzata
Documentario sull'edificio per uffici VO
PubblicitàAvanzatoDocumentario immobiliare con clonazione del riferimento vocale
Dalle foto dell'edificio per uffici fornite, genera un documentario cinematografico di 15 secondi, 2.35:1 widescreen, 24fps, immagini raffinate, tono della voce fuori campo riferimento @video1...
Immagini di riferimento
1
Immagini di riferimento 1: Documentario sull'edificio per uffici VO
2
Immagini di riferimento 2: Documentario sull'edificio per uffici VO
3
Immagini di riferimento 3: Documentario sull'edificio per uffici VO
Video di riferimento
1 Video di riferimento 1: Documentario sull'edificio per uffici VO
Risultato generato
Risultato generato: Documentario sull'edificio per uffici VO — Documentario immobiliare con clonazione del riferimento vocale
Talk show su cani e gatti
Breve videoPrincipianteGenerazione di dialoghi comici con espressione emotiva
Segmento talk show tra gatto e cane, emotivamente ricco, stile stand-up comedy...
Immagini di riferimento
1
Immagini di riferimento 1: Talk show su cani e gatti
Risultato generato
Risultato generato: Talk show su cani e gatti — Generazione di dialoghi comici con espressione emotiva
Yu opera Caso Chen Shimei
Musica MVIntermedioSpettacolo d'opera tradizionale con voce sincronizzata
Accompagnamento Yu opera 'Esecuzione di Chen Shimei', Bao Zheng in nero punta Chen in rosso, canta ferocemente. Occhi di Chen si muovono nervosamente, ruolo dan: Aspetta!
Immagini di riferimento
1
Immagini di riferimento 1: Yu opera Caso Chen Shimei
Risultato generato
Risultato generato: Yu opera Caso Chen Shimei — Spettacolo d'opera tradizionale con voce sincronizzata
Banda MV tramonto sulla scogliera
Musica MVIntermedioVideo musicale cinematografico con audio atmosferico
Genera 15s MV. Composizione stabile, leggera push-pull, inquadratura eroica a basso angolo, establishing ultra-wide, strada scogliera e camper vintage, orizzonte marino, controluce al tramonto volumetrico, inquadratura cinematografica.
Immagini di riferimento
1
Immagini di riferimento 1: Banda MV tramonto sulla scogliera
Risultato generato
Risultato generato: Banda MV tramonto sulla scogliera — Video musicale cinematografico con audio atmosferico
Festa della famiglia latina
Musica MVIntermedioScena di celebrazione guidata dalla musica con audio culturale
Ragazza con cappello al centro canta dolcemente Sono così orgoglioso della mia famiglia! si gira per abbracciare la ragazza di colore. Musica latina, gonne che oscillano, strade colorate che ballano.
Immagini di riferimento
1
Immagini di riferimento 1: Festa della famiglia latina
Risultato generato
Risultato generato: Festa della famiglia latina — Scena di celebrazione guidata dalla musica con audio culturale
Squadra tattica spagnola
GiocoIntermedioDialogo multilingue per i filmati del gioco
Ripresa fissa. Capitano in spagnolo: Raid tra tre minuti! Biondo controlla le armi, capelli verdi tiene la torcia tattica. Compagno nero: Flanking? Capitano: Come sempre, tieni uno per interrogatorio.
Immagini di riferimento
1
Immagini di riferimento 1: Squadra tattica spagnola
Risultato generato
Risultato generato: Squadra tattica spagnola — Dialogo multilingue per i filmati del gioco
Riferimento vocale per la sveglia
PellicolaIntermedioClonazione vocale per scene di dialogo narrativo
0-3s: Ripresa fissa, ragazza da @image1 addormentata nel letto. 3-10s: Quick pan al primo piano del viso dell'uomo (@image2), uomo la sveglia con aria disperata, tono e voce riferimento @video1.
Immagini di riferimento
1
Immagini di riferimento 1: Riferimento vocale per la sveglia
2
Immagini di riferimento 2: Riferimento vocale per la sveglia
Video di riferimento
1 Video di riferimento 1: Riferimento vocale per la sveglia
Risultato generato
Risultato generato: Riferimento vocale per la sveglia — Clonazione vocale per scene di dialogo narrativo
Tè delle bolle delle scimmie Sichuan
Breve videoIntermedioDialogo dialettale regionale per contenuti divertenti
Scimmia da @image1 va al banco del bubble tea, @image2 addetto Bichon pulisce gli strumenti, scimmia ordina in dialetto Sichuan: Ehi, hai Farewell My Concubine?
Immagini di riferimento
1
Immagini di riferimento 1: Tè delle bolle delle scimmie Sichuan
2
Immagini di riferimento 2: Tè delle bolle delle scimmie Sichuan
3
Immagini di riferimento 3: Tè delle bolle delle scimmie Sichuan
Risultato generato
Risultato generato: Tè delle bolle delle scimmie Sichuan — Dialogo dialettale regionale per contenuti divertenti
Montagna della fiamma del Re Scimmia
IstruzioneIntermedioNarrazione educativa con audio narrativo
Stile e tono educativo, metti in scena il contenuto di @image1: Monkey King attraversa la Montagna di Fuoco per prendere in prestito il ventaglio dalla Principessa Iron Fan, lei cerca vendetta per Red Boy, lui supplica invano, litigano.
Immagini di riferimento
1
Immagini di riferimento 1: Montagna della fiamma del Re Scimmia
Risultato generato
Risultato generato: Montagna della fiamma del Re Scimmia — Narrazione educativa con audio narrativo