Sprachreferenz für den Weckruf
Präzise Stimme und Ton
0-3s: Fester Shot, Mädchen aus @image1 schläft im Bett. 3-10s: Schneller Schwenk zu Manns Gesicht (@image2), Mann weckt sie hilflos, Ton und Stimme Referenz @video1.
Referenzdaten
Erzeugen Sie Sprache, Atmosphäre und Musik zusammen mit der Videoausgabe. So funktioniert es: Anstatt stummes Video zu generieren und Audio in der Nachbearbeitung hinzuzufügen, produziert das Modell Bild und Ton im selben Durchgang. Es liest den visuellen Kontext — Lippenbewegungen der Charaktere, Umgebungstyp, Aktionsintensität — und erzeugt passende Stimme, Atmosphäre, Soundeffekte oder Hintergrundmusik. Text-Prompts können den Audiostil steuern (‘fröhlicher elektronischer BGM’, ‘sanfte Wald-Ambientklänge’, ‘weiblicher Voiceover auf Englisch’). Wann Sie dies verwenden sollten: Werbeproduktion, bei der jede Variante lokalisierten Voiceover benötigt; Social-Media-Kurzvideos, bei denen BGM und Timing wichtig sind, manuelle Synchronisation aber zu langsam ist; Prototyping von Szenen, bei denen Sie Bild und Ton gemeinsam bewerten möchten, bevor Sie in professionelles Audio investieren; mehrsprachige Inhalte, bei denen dasselbe Video Voiceovers in verschiedenen Sprachen benötigt. Tipps und praktische Hinweise: Für beste Lippensynchronisationsergebnisse halten Sie Gesichter von Charakteren deutlich sichtbar und unverdeckt. Geben Sie Sprache und Tonfall in Ihrem Prompt an — ‘ruhiger männlicher Erzähler auf Japanisch’ liefert bessere Ergebnisse als nur ‘Stimme hinzufügen.’ Wenn Sie natives Audio mit Musiksynchronisation kombinieren, kann das Modell BGM-Beat-Ausrichtung und Dialog gleichzeitig verarbeiten. Überprüfen Sie das Audio im ersten Durchgang, um Timing-Probleme frühzeitig zu erkennen, anstatt viele Varianten zu generieren, bevor Sie prüfen.
Wenn für ein Video noch Hintergrundmusik, Atmosphäre oder lippensynchrone Dialoge erforderlich sind, kann das Modell Bild und Ton zusammen erzeugen, sodass diese Audiooptionen im selben Durchgang überprüft werden können.
Präzise Stimme und Ton
Sprachreferenz für den Weckruf
Seedance 2.0 generiert Stimme, Soundeffekte und Musik zusammen mit dem Video in einem Durchgang — mit Lippensynchronisation, mehrsprachiger Unterstützung und einer Unilever-Massenproduktions-Fallstudie.
FähigkeitenAlle Beispiele
Verwandte Leitfäden
Leitfaden
Was ist Seedance 2.0 von ByteDance? Offizielle Website, Release-Datum und Zugang
Aktueller öffentlicher Überblick zu Seedance 2.0 von ByteDance: offizielle Website, Release-Datum 12. Februar 2026, Zugangssignale über Dreamina, multimodale Eingaben, 2K-/15-Sekunden-Output und was bei der Verfügbarkeit weiter plattformabhängig bleibt.
Leitfaden öffnenLeitfaden
Seedance 2.0 Omni-Reference & Multimodale Eingabe — Bilder, Video & Audio-Referenzen erklärt
Multimodale Eingaben in Seedance 2.0: bis zu 9 Bilder, 3 Videos, 3 Audios plus Text. Mit @-Tags auf Assets verweisen und Audio/Video nativ gemeinsam erzeugen.
Leitfaden öffnenLeitfaden
Seedance 2.0 Anwendungsfälle — Praxisbeispiele für Werbung, Film, Bildung & mehr
Anwendungsfälle für Seedance 2.0: E-Commerce-Anzeigen, TVC, Produktdemos, Film-Previz, MV, Bildung, Immobilien und kurze Narration. Basierend auf offiziellem Blog und Fallstudien aus Drittquellen.
Leitfaden öffnenLeitfaden
Promo videos stitched from multiple clips: workflow field notes
Honest workflow notes when a longer promo is built from several Seedance 2.0 generations: unified references, the per-clip duration cap, audio continuity, and dialogue pacing.
Leitfaden öffnenLeitfaden
Seedance 2.0 Shot Design Workflow — Cinema-Grade Video Prompts
Master the 5-step shot design workflow for Seedance 2.0: from requirement analysis through visual diagnosis, six-element assembly, validation, to professional delivery. Includes 28+ director presets, three-layer lighting, and multi-segment storyboarding.
Leitfaden öffnenLeitfaden
Short-Form Social Video with Seedance-Style Models — Reels, Shorts, TikTok-Class Pacing (2026)
Vertical aspect ratios, hook-first prompting, and audio loudness considerations for algorithmic feeds — third-party workflow notes.
Leitfaden öffnenVerwandte Funktionen

Musiksynchronisierung
Beat-synchronisierte Musik und Rhythmus-Anpassung.
Musik hochladen; Videoschnitte und Bewegung passen sich dem Takt an.
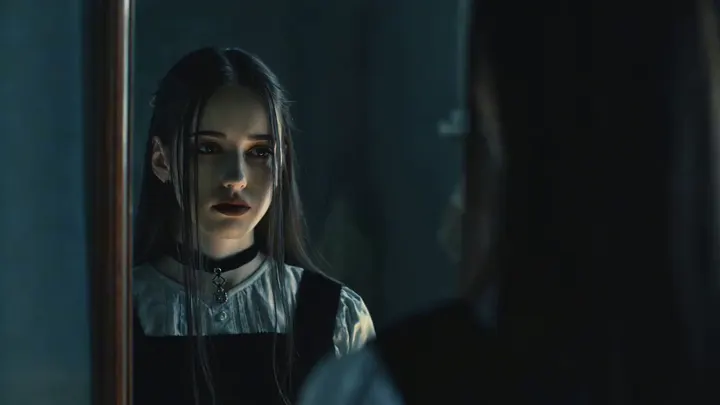
Emotionsausdruck
Bessere emotionale Leistung und Ausdruck.
Der Charakter zeigt Freude, Traurigkeit, Überraschung; natürliche Gesichts- und Körpersprache.

Videobearbeitung
Ersetzen, Beschneiden und Hinzufügen von Zeichen.
Inpainting, Zeichenaustausch, Hintergrunderweiterung, Hinzufügen von /remove-Elementen; kein Nachschießen.