Té de burbujas de mono Sichuan
Voz y sonido precisos
Mono de @image1 va al mostrador de té con burbujas, @image2 Bichon limpia herramientas, mono pide en dialecto Sichuan: ¿Tienes Adiós mi concubina?
Datos de referencia
Genera voz, ambiente y música junto con la salida de video. Cómo funciona: en lugar de generar video silencioso y añadir audio en posproducción, el modelo produce imagen y sonido en la misma pasada. Lee el contexto visual — movimientos labiales de personajes, tipo de entorno, intensidad de la acción — y genera voz, ambiente, efectos de sonido o música de fondo que coincidan. Los prompts de texto pueden guiar el estilo de audio ('BGM electrónico animado', 'sonidos suaves de bosque ambiental', 'locución femenina en inglés'). Cuándo usarlo: producción publicitaria donde cada variante necesita locución localizada; cortos de redes sociales donde el BGM y el timing importan pero la sincronización manual es demasiado lenta; prototipado de escenas donde quieres evaluar imagen y sonido juntos antes de invertir en audio profesional; contenido multilingüe donde el mismo video necesita locuciones en diferentes idiomas. Consejos y notas prácticas: para mejores resultados de sincronización labial, mantén los rostros de los personajes claramente visibles y sin obstrucciones. Especifica el idioma y tono de voz en tu prompt — 'narrador masculino calmado en japonés' da mejores resultados que simplemente 'añadir voz'. Al combinar audio nativo con sincronización musical, el modelo puede manejar la alineación de ritmo del BGM y el diálogo simultáneamente. Revisa el audio en la primera pasada para detectar problemas de timing temprano en lugar de generar muchas variantes antes de verificar.
Si un vídeo aún necesita música de fondo, ambiente o diálogo sincronizado con los labios, el modelo puede generar imagen y sonido juntos para que esas opciones de audio se puedan revisar en la misma pasada.
Voz y sonido precisos
Té de burbujas de mono Sichuan
Seedance 2.0 genera voz, efectos de sonido y música junto con el video en una sola pasada — con sincronización labial, soporte multilingüe y caso de estudio de producción masiva de Unilever.
CapacidadesTodos los ejemplos
- Música de fondo de caballo con ojo de pez (varios vídeos)
- Documental sobre el edificio de oficinas VO
- Programa de entrevistas sobre perros y gatos
- Ópera Yu 铡美案
- Banda MV atardecer en el acantilado
- Celebración familiar latina
- Escuadra táctica española
- Referencia de voz de llamada de despertador
- Té de burbujas de mono Sichuan
- Montaña de llamas del Rey Mono
Guías relacionadas
Guía
¿Qué es Seedance 2.0 de ByteDance? Sitio oficial, fecha de lanzamiento y acceso
Resumen público actual de Seedance 2.0 de ByteDance: sitio oficial, fecha de lanzamiento del 12 de febrero de 2026, señales de acceso en Dreamina, entradas multimodales, salidas de 2K / 15 segundos y qué sigue dependiendo de la disponibilidad.
Abrir guíaGuía
Seedance 2.0 Omni-Reference & Entrada Multimodal — Imágenes, Vídeo y Audio de referencia explicados
Entrada multimodal de Seedance 2.0: hasta 9 imágenes, 3 videos, 3 audios y texto. Sistema de etiquetas @ para referenciar recursos y generación conjunta nativa de audio y video.
Abrir guíaGuía
Seedance 2.0 Casos de uso — Ejemplos reales para publicidad, cine, educación y más
Casos de uso de Seedance 2.0: anuncios para e-commerce, TVC, demos de producto, previz cinematográfica, MV, educación, inmobiliario y narrativa breve. Basado en el blog oficial y casos de terceros.
Abrir guíaGuía
Promo videos stitched from multiple clips: workflow field notes
Honest workflow notes when a longer promo is built from several Seedance 2.0 generations: unified references, the per-clip duration cap, audio continuity, and dialogue pacing.
Abrir guíaGuía
Seedance 2.0 Shot Design Workflow — Cinema-Grade Video Prompts
Master the 5-step shot design workflow for Seedance 2.0: from requirement analysis through visual diagnosis, six-element assembly, validation, to professional delivery. Includes 28+ director presets, three-layer lighting, and multi-segment storyboarding.
Abrir guíaGuía
Short-Form Social Video with Seedance-Style Models — Reels, Shorts, TikTok-Class Pacing (2026)
Vertical aspect ratios, hook-first prompting, and audio loudness considerations for algorithmic feeds — third-party workflow notes.
Abrir guíaCapacidades relacionadas

Sincronización de música
Música sincronizada con ritmos y alineación de ritmos.
Subir música; Los cortes de vídeo y el movimiento se alinean con el ritmo.
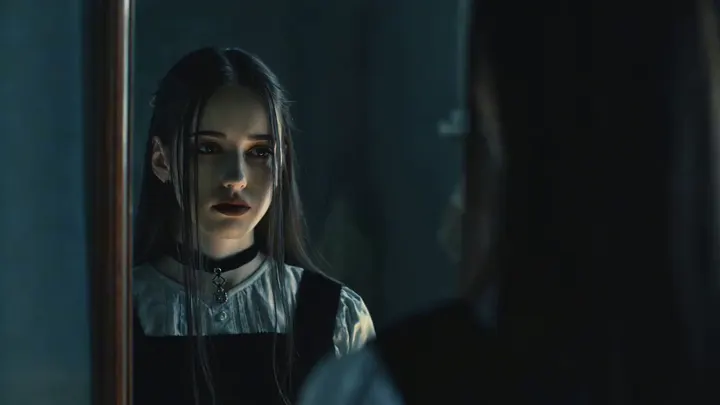
Expresión de emoción
Mejor rendimiento y expresión emocional.
El personaje muestra alegría, tristeza, sorpresa; rostro y lenguaje corporal natural.

Edición de vídeo
Reemplazo, recorte y adiciones de personajes.
Pintura interna, intercambio de personajes, extensión de fondo, agregar elementos /remove; no volver a disparar.