Referência de voz para chamada de despertar
Voz e som precisos
0-3s: Plano fixo, garota de @image1 dormindo na cama. 3-10s: Pan rápido para close do rosto do homem (@image2), homem a acorda com resignação, tom e voz referência @video1.
Dados de referência
Gere voz, ambiente e música junto com a saída de vídeo. Como funciona: em vez de gerar vídeo silencioso e adicionar áudio na pós-produção, o modelo produz imagem e som na mesma passagem. Ele lê o contexto visual — movimentos labiais dos personagens, tipo de ambiente, intensidade da ação — e gera voz, ambiente, efeitos sonoros ou música de fundo correspondentes. Prompts de texto podem guiar o estilo do áudio ('BGM eletrônico animado', 'sons ambientes suaves de floresta', 'narração feminina em português'). Quando usar: produção de anúncios onde cada variante precisa de narração localizada; vídeos curtos para redes sociais onde BGM e timing importam mas sincronização manual é lenta demais; prototipagem de cenas onde você quer avaliar imagem e som juntos antes de investir em áudio profissional; conteúdo multilíngue onde o mesmo vídeo precisa de narrações em diferentes idiomas. Dicas e notas práticas: para melhores resultados de sincronização labial, mantenha os rostos dos personagens claramente visíveis e desobstruídos. Especifique o idioma e o tom de voz no seu prompt — 'narrador masculino calmo em japonês' dá melhores resultados do que apenas 'adicionar voz.' Ao combinar áudio nativo com sincronização musical, o modelo pode lidar com alinhamento de batidas do BGM e diálogo simultaneamente. Revise o áudio na primeira passagem para identificar problemas de timing cedo, em vez de gerar muitas variantes antes de verificar.
Se um vídeo ainda precisar de música de fundo, ambiente ou diálogo sincronizado com os lábios, o modelo pode gerar imagem e som juntos para que essas opções de áudio possam ser revisadas na mesma passagem.
Voz e som precisos
Referência de voz para chamada de despertar
Seedance 2.0 gera voz, efeitos sonoros e música junto com o vídeo em uma única passagem — com sincronização labial, suporte multilíngue e estudo de caso de produção em massa da Unilever.
CapacidadesTodos os exemplos
- Cavalo olho de peixe BGM (multi-vídeo)
- Documentário sobre prédio de escritórios VO
- Talk show sobre cães e gatos
- Ópera Yu 铡美案
- Banda MV pôr do sol no penhasco
- Celebração da família latina
- Esquadrão Tático Espanhol
- Referência de voz para chamada de despertar
- Chá de bolha de macaco Sichuan
- Montanha de Chamas do Rei Macaco
Guias relacionados
Guia
O que é o Seedance 2.0 da ByteDance? Site oficial, data de lançamento e acesso
Visão pública atual do Seedance 2.0 da ByteDance: site oficial, data de lançamento de 12 de fevereiro de 2026, sinais de acesso no Dreamina, entradas multimodais, saídas de 2K / 15 segundos e o que ainda depende da superfície usada.
Abrir guiaGuia
Seedance 2.0 Omni-Reference & Entrada Multimodal — Imagens, Vídeo e Áudio de referência explicados
Seedance 2.0 Entrada multimodal: até 9 imagens, 3 vídeos, 3 áudio + texto. @ tag system para referenciar ativos. Geração conjunta de áudio-vídeo nativo.
Abrir guiaGuia
Seedance 2.0 Casos de uso — Exemplos reais para publicidade, cinema, educação e mais
Seedance 2.0 Casos de uso: anúncios de e-commerce, TVC, demos de produtos, filme pré-viz, MV, educação, imóveis e narrativa curta. Baseado em blog oficial e estudos de caso de terceiros.
Abrir guiaGuia
Promo videos stitched from multiple clips: workflow field notes
Honest workflow notes when a longer promo is built from several Seedance 2.0 generations: unified references, the per-clip duration cap, audio continuity, and dialogue pacing.
Abrir guiaGuia
Seedance 2.0 Shot Design Workflow — Cinema-Grade Video Prompts
Master the 5-step shot design workflow for Seedance 2.0: from requirement analysis through visual diagnosis, six-element assembly, validation, to professional delivery. Includes 28+ director presets, three-layer lighting, and multi-segment storyboarding.
Abrir guiaGuia
Short-Form Social Video with Seedance-Style Models — Reels, Shorts, TikTok-Class Pacing (2026)
Vertical aspect ratios, hook-first prompting, and audio loudness considerations for algorithmic feeds — third-party workflow notes.
Abrir guiaCapacidades relacionadas

Sincronização de música
Música sincronizada com batida e alinhamento de ritmo.
Carregar música; cortes de vídeo e movimentos alinhados à batida.
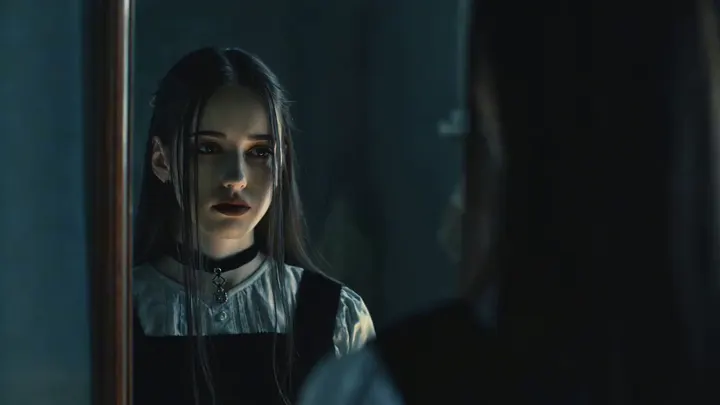
Expressão Emocional
Melhor desempenho e expressão emocional.
O personagem demonstra alegria, tristeza, surpresa; rosto natural e linguagem corporal.

Edição de vídeo
Substituição, corte e acréscimos de caracteres.
Pintura interna, troca de caracteres, extensão de fundo, adição de elementos/remove; sem refilmagem.